Sample weighting¤
![]()
This example illustrates how to weigh individual training samples differently with klax.fit by using a custom loss function.
To run it locally install klax with plotting capability via pip install 'klax[plot]'.
We'll start by importing the required packages for model creation, optimization and plotting.
import jax
from jax import numpy as jnp
from jax import random as jr
from matplotlib import pyplot as plt
import klax
key = jr.key(0)
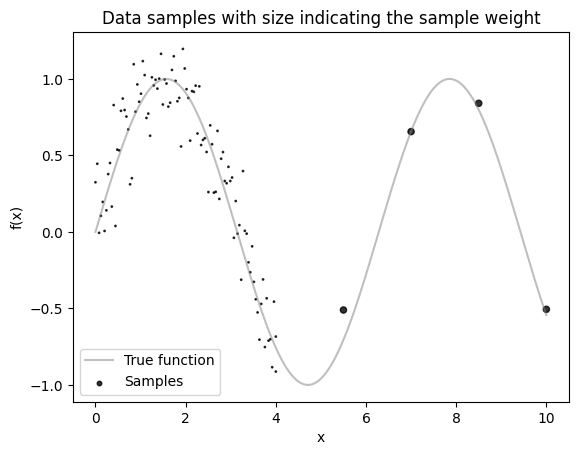
First, we generate some dummy data along with sample weights.
Assume our data comes from the function \(f(x) = \sin(x) + \mathcal{N}(0, 0.2)\).
In practice, we don’t have direct access to the underlying function and only observe sampled points.
Importantly, our samples are not uniformly distributed: we have many more data points in the region \(x \in [0, 4]\) than in \(x \in [4, 10]\).
To prevent the model from focusing disproportionately on the dense region, we assign larger sample weights to points in the sparser region.
def f(x):
return jnp.sin(x)
x_samples = jnp.concat([jnp.linspace(0, 4, 100), jnp.linspace(4, 10, 5)])
y_samples = f(x_samples) + 0.2 * jr.normal(key, shape=x_samples.shape)
sample_weights = jnp.where(x_samples > 4, 20, 1)
x_dense = jnp.linspace(0, 10, 1000)
y_dense = f(x_dense)
# Plot the data
plt.plot(x_dense, y_dense, c="grey", label="True function", alpha=0.5)
plt.scatter(
x_samples, y_samples, c="k", s=sample_weights, alpha=0.8, label="Samples"
)
plt.gca().set(
xlabel="x",
ylabel="f(x)",
title="Data samples with size indicating the sample weight",
)
plt.legend()
plt.show()
Let's fit a simple klax.nn.MLP to this data.
Let's first create a custom loss function that computes a weighted mean squared error. To pass the weights to the loss function we integrate the sample weights into the dataset.
For comparison we also train an identical model without the sample weighting.
@klax.loss
def custom_loss(model, data, run_state):
inputs, targets, weights = data
predictions = jax.vmap(model)(inputs)
weighted_mse = jnp.mean(weights * (predictions - targets) ** 2)
return weighted_mse
model_key, training_key = jr.split(key)
model = klax.nn.MLP(
in_size="scalar", out_size="scalar", width_sizes=[8, 8], key=model_key
)
model, history = klax.fit(
model,
data=(x_samples, y_samples, sample_weights),
loss=custom_loss,
batch_size=32,
steps=20_000,
log_every=100,
key=training_key,
)
baseline_model = klax.nn.MLP(
in_size="scalar", out_size="scalar", width_sizes=[8, 8], key=model_key
)
baseline_model, baseline_history = klax.fit(
baseline_model,
data=(x_samples, y_samples),
batch_size=32,
steps=20_000,
log_every=100,
key=training_key,
)
0%| | 0/20000 [00:00<?, ?it/s]
0%| | 0/20000 [00:00<?, ?it/s]
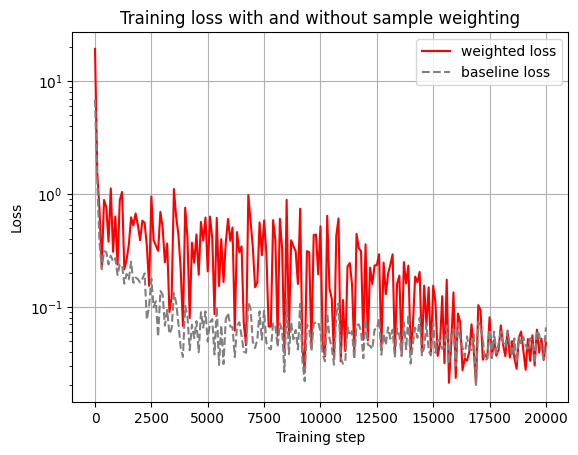
ax = history.plot(c="red")
baseline_history.plot(ax=ax, ls="--", c="grey")
ax.set(
xlabel="Training step",
ylabel="Loss",
title="Training loss with and without sample weighting",
yscale="log",
)
plt.legend(["weighted loss", "baseline loss"])
plt.show()
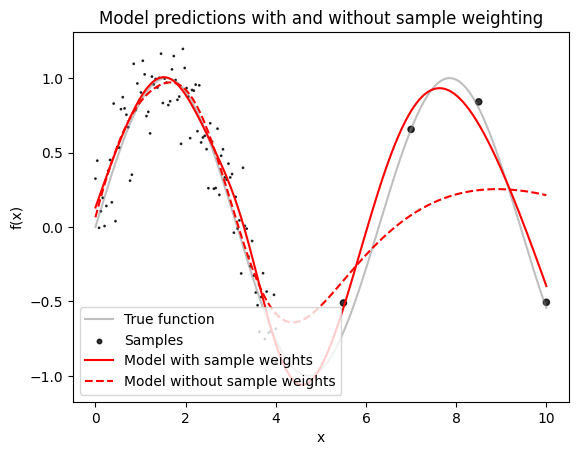
Let's plot the model predictions.
# Plot the data
y_pred = jax.vmap(model)(x_dense)
y_pred_baseline = jax.vmap(baseline_model)(x_dense)
plt.plot(x_dense, y_dense, c="grey", label="True function", alpha=0.5)
plt.scatter(
x_samples, y_samples, c="k", s=sample_weights, alpha=0.8, label="Samples"
)
plt.plot(x_dense, y_pred, c="red", label="Model with sample weights")
plt.plot(
x_dense,
y_pred_baseline,
c="red",
label="Model without sample weights",
ls="--",
)
plt.gca().set(
xlabel="x",
ylabel="f(x)",
title="Model predictions with and without sample weighting",
)
plt.legend(loc=3)
plt.show()